一、HetGNN [2019]
《Heterogeneous Graph Neural Network》
异质图(
heterogeneous graph: HetG)包含多种类型的节点,以及节点之间的多种关系。如下图的学术网络包含了author节点、paper节点以及venue节点,并包含了author和paper之间的write关系、paper和paper之间的cite关系、paper和venue之间的publish关系。此外,节点还具有属性(author id)以及文本(论文摘要)等特征。异质图的这种普遍性导致大量的研究开始涌入相应的图挖掘方法和算法,例如关系推理(relation inference)、个性化推荐、节点分类等等。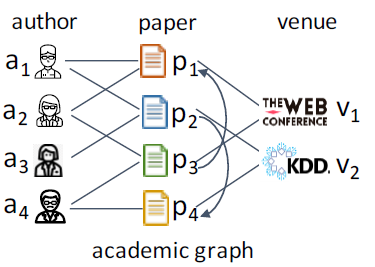
传统的异质图任务中,很多方法都依赖于从手工特征中得到特征向量。这种方式需要分析和计算有关异质图的不同统计特性和属性,从而作为下游机器学习任务的特征向量。但是这种方式仅局限于当前任务,无法推广到其它任务。近期出现的
representation learning方法使得特征工程自动化,从而促进下游的机器学习任务。从同质图开始,graph representation learning已经扩展到异质图、属性图、以及特定的图。例如:shallow model(如DeepWalk)最初是为了将图上的短随机游走的集合提供给SkipGram模型,从而近似(approximate)这些游走中的节点共现概率(node co-occurrence probability)并获得node embedding。随后,人们提出了语义感知(
semantic-aware)方法(如metapath2vec),从而解决异质图中的节点异质性(node heterogeneity)和关系异质性(relation heterogeneity)。此外,内容感知方法(如
ASNE)利用latent feature和属性来学习图中的node embedding。
这些方法直接学习节点的潜在
embedding,但是在捕获丰富的邻域信息方面受到限制。图神经网络GNN采用深度神经网络来聚合邻域节点的特征信息,这使得aggregated embedding更加强大。此外,GNN可以自然地应用于inductive任务,该任务涉及到训练期间unseen的节点。例如,GCN, GraphSAGE, GAT分别采用卷积操作、LSTM架构、以及注意力机制来聚合邻域节点的特征信息。GNN的进步和应用主要集中在同质图上。但是,当前SOTA的GNN无法解决异质图学习的以下问题:问题
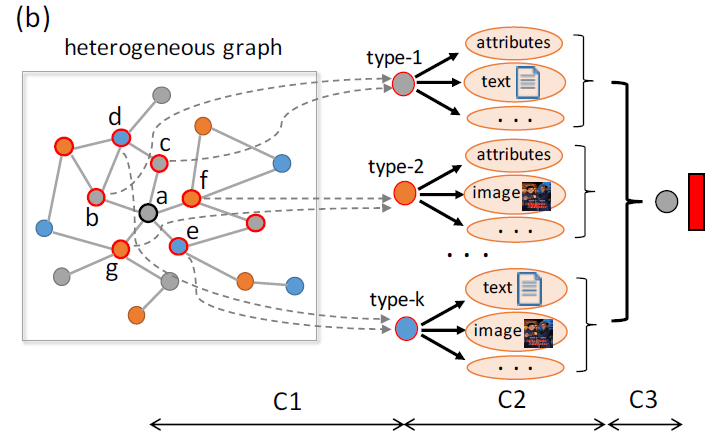
C1:异质图中很多节点连接到多种类型的邻居,连接的邻居节点的种类和数量可能各不相同。例如,下图中节点a有5个直接邻居而节点c只有2个直接邻居。现有的大多数
GNN仅聚合直接邻域的特征信息,而特征传播过程可能会削弱更远邻域的影响。此外,hub节点的embedding生成受到弱相关的邻居(即,噪声邻居)的影响,并且“冷启动”节点的embedding无法充分地被表达(由于邻域信息有限所导致)。第一个问题是:如何对每个节点采样和它
embedding最相关的异质邻居?如下图中的C1阶段所示。问题
C2:异质图中的节点可能具有非结构化的异质内容,如属性、文本、图像等。另外,不同类型节点关联的内容可能有所不同。如下图中:type-1的节点(如b,c)关联的内容为属性、文本。type-2的节点(如f,g)关联的内容为属性、图像。type-k的节点(如d,e)关联的内容为文本、图像。
当前
GNN的直接拼接操作或者线性变换操作无法对节点异质内容之间的深层交互(deep interaction)进行建模。而且,由于不同类型节点的内容多种多样,因此针对所有类型节点使用相同的特征变换函数是不合适的。第二个问题是:如何设计节点内容encoder,从而编码异质图中不同节点的内容异质性?如下图中的C2阶段所示。问题
C3:不同类型的邻居对异质图中node embedding的贡献不同。如学术网络中,author和paper类型的邻居对author节点的embedding产生更大的影响,因为venue类型的节点包含多样化的主题因此具有更general的embedding。当前大多数GNN仅关于同质图,并未考虑节点类型的影响。第三个问题是:如何考虑不同类型节点的影响,从而聚合异质邻居的特征信息。如下图中的C3阶段所示。
为解决这些问题,论文
《Heterogeneous Graph Neural Network》提出了heterogeneous graph neural network: HetGNN。HetGNN是一种用于异质图的representation learning图神经网络模型。首先,作者设计了一种基于重启的随机游走策略,从而对异质图中每个节点采样固定大小的、强相关的异质邻域,并根据节点类型对其进行分组。
然后,作者设计了一个具有两个模块的异质图神经网络体系结构,从而聚合上一步中采样到的邻居的特征信息。
第一个模块采用
RNN对异质内容的deep interaction进行编码,从而获得每个节点的内容embedding。因为单个节点可能具有多个内容(既有文本又有图像),因此需要通过一个模块来融合多种不同的内容从而得到内容
embedding。第二个模块采用另一个
RNN来聚合不同分组邻居的内容embedding,然后通过注意力机制将其进一步组合,从而区分不同异质节点类型的影响,并获得最终embedding。
最后,论文利用图上下文损失(
graph context loss)和mini-batch随机梯度下降来训练模型。
总而言之,论文的主要贡献:
论文形式化了异质图
representation learning的问题,该问题涉及到图结构异质性和节点内容异质性。论文提出了一种创新的异质图神经网络模型(
heterogeneous graph neural network model: HetGNN),用于异质图上的representation learning。HetGNN能够捕获结构异质性和内容异质性,并对transductive task和inductive task都很有用。下表总结了HetGNN与最近的一些模型(包括同质图模型、异质图模型、属性图模型、以及图神经网络模型)相比的主要优势。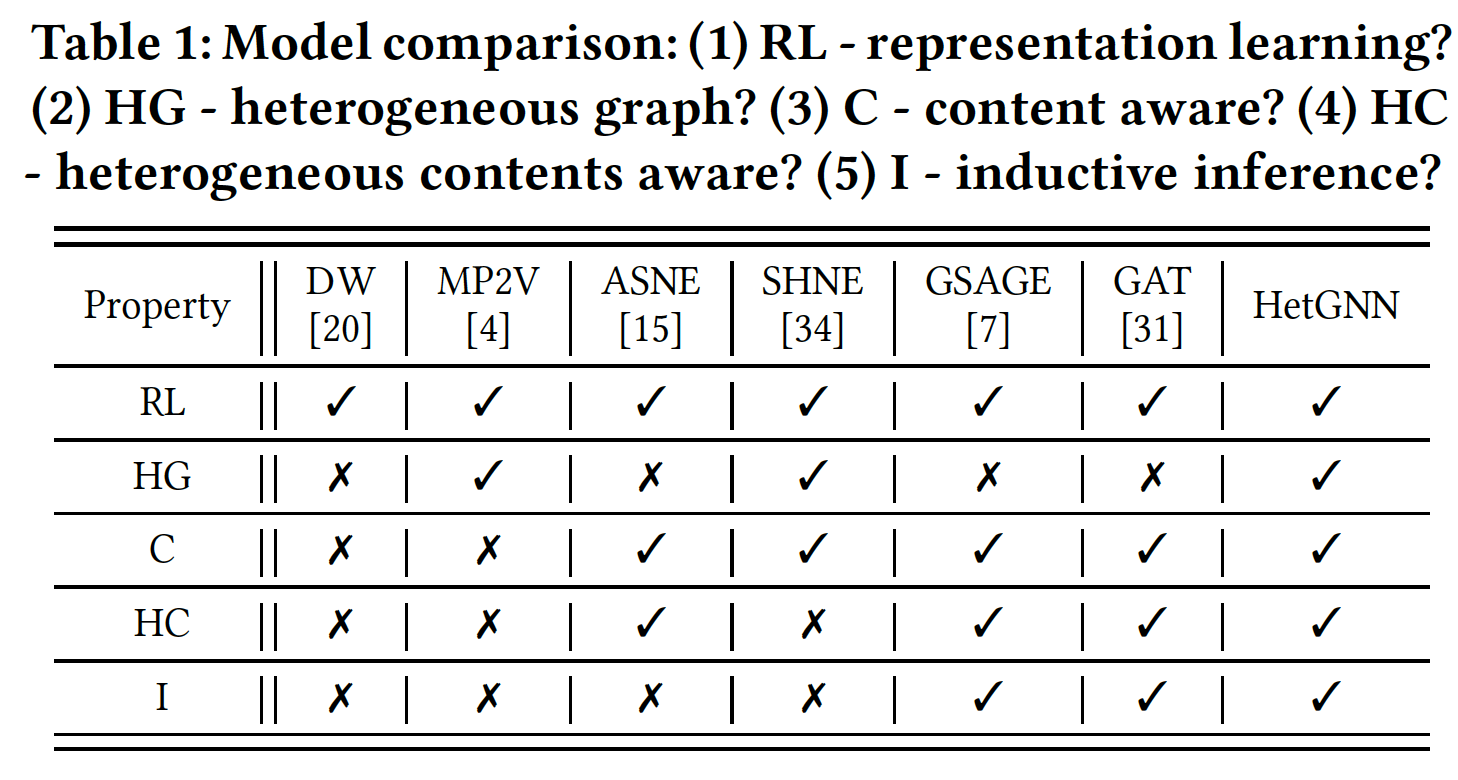
论文在几个公共数据集上进行了广泛的实验,结果表明:
HetGNN在各种图数据挖掘任务(链接预测、推荐、节点分类、聚类)中可以超越SOTA的baseline方法。
相关工作:
异质图挖掘(
heterogeneous graph mining):在过去的十年中,许多工作致力于挖掘异质图从而用于不同的application,如关系推断、个性化推荐、节点分类等等。《When will it happen?: relationship prediction in heterogeneous information networks》利用metapath-based方法来抽取拓扑特征并预测学术图academic graph中的引用关系。《Task-Guided and Path-Augmented Heterogeneous Network Embedding for Author Identification》设计了一个基于异质图的ranking model来识别匿名论文的作者。《Deep Collective Classification in Heterogeneous Information Networks》提出了一种深度卷积分类模型,用于异质图中的collective classification。
图表示学习(
graph representation learning):graph epresentation learning已经成为过去几年最流行的数据挖掘主题之一。人们提出了基于图结构的模型来学习向量化的node embedding从而进一步用于下游各种图挖掘任务。受到
word2vec的启发,《Deepwalk: Online learning of social representations》创新性地提出了DeepWalk,它在图中引入了node-context的概念(类比于word-context),并将图上的随机游走的集合(类比于sentence集合)提供给SkipGram从而获得node embedding。后来,为了解决图结构的异质性,
《metapath2vec: Scalable Representation Learning for Heterogeneous Networks》引入了metapath-guided随机游走,并提出metapath2vec模型来用于异质图中的representation learning。此外,人们已经提出了属性图嵌入模型(
《Attributed network embedding for learning in a dynamic environment》、《Attributed social network embedding》、《SHNE: Representation Learning for Semantic-Associated Heterogeneous Networks》)来利用图结构和节点属性来学习node embedding。除了这些方法之外,人们还提出了许多其它方法(
《Heterogeneous network embedding via deep architectures》、《Hierarchical Taxonomy Aware Network Embedding》、《Network embedding as matrix factorization: Unifying deepwalk, line, pte, and node2vec》、《Pte: Predictive text embedding through large-scale heterogeneous text networks》、《Learning Deep Network Representations with Adversarially Regularized Autoencoders》)。
图神经网络(
graph neural networks):最近,随着深度学习的出现,图神经网络获得了很多关注。与之前的graph embedding模型不同,GNN背后的关键思想是:通过神经网络从节点的局部邻域中聚合特征信息。Graph-SAGE使用神经网络(如LSTM)来聚合邻域的特征信息。GAT使用自注意力机制来衡量不同邻居的影响力,并结合它们的影响力来获得node embedding。此外,人们已经提出了一些
task dependent的方法从而为特定任务获得更好的node embedding,例如用于恶意账户检测的GEM(《Heterogeneous Graph Neural Networks for Malicious Account Detection》)。
1.1 模型
定义一个带内容的异质图(
content associated heterogeneous graph:C-HetG)为attribute)、文本(text)、图像(image)。给定一个
C-HetGHeterogenous Graph Representation Learning)的目标是设计一个模型embedding,从而能够同时编码异质结构信息和异质内容信息,其中学到的
node embedding可以应用于下游各种图挖掘任务,如链接预测、推荐、多标签分类、节点聚类等。我们首先给出
HetGNN的整体框架如下图所示,其中包含四个部分:对异质邻居节点进行采样、编码节点的异质内容、聚合节点的异质邻居、定义目标函数并给出训练过程。下图中:
图
(a)为整体框架:首先为每个节点(以节点
a为例)采样固定数量的异质邻居节点。然后通过
NN-1神经网络编码每个节点的异质内容。然后通过
NN-2神经网络和NN-3神经网络来聚合采样到的异质邻居节点的内容embedding。最后通过图上下文损失函数来优化模型。
图
(b)为NN-1神经网络,它是节点异质内容编码器。图
(c)为NN-2神经网络,它是type-based邻域聚合器。图
(d)为NN-3神经网络,它是异质类型组合器。
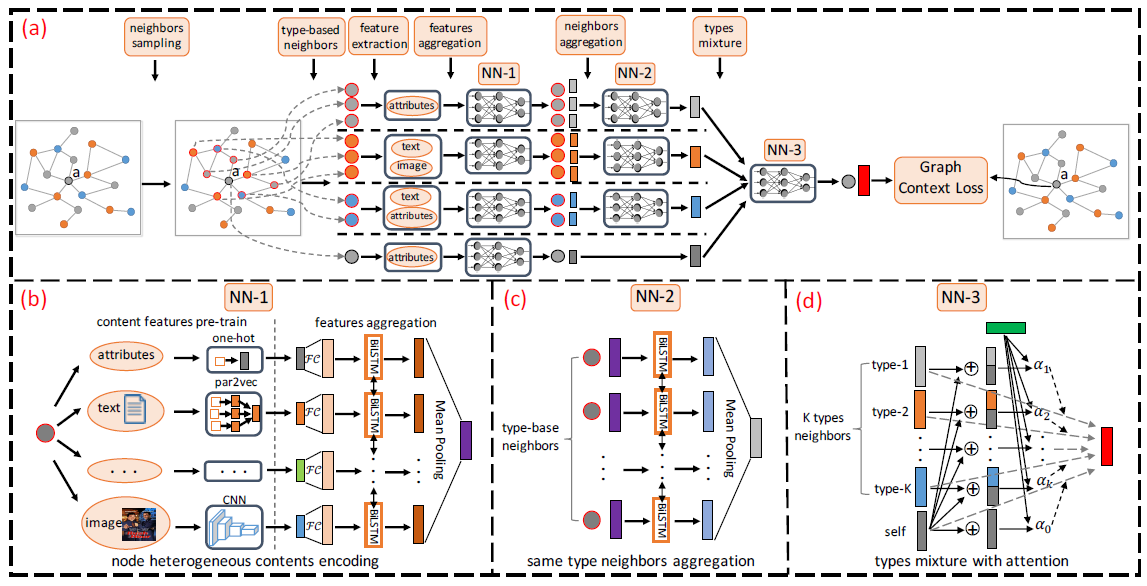
1.1.1 异质邻居采样
大多数神经网络
GNN的关键思想是聚合来自节点的直接邻居(一阶邻居)的特征信息,如GraphSAGE或GAT。但是,直接将这些方法应用到异质图可能会引起一些问题:它们无法从不同类型的异质邻居的直接链接中捕获充分的信息。如,在学术网络中,
author并未和其它author或venue直接相连,但是可能存在间接连接。如果仅考虑直接连接的邻居,则可能导致学到的representation表达能力不足。embedding可能受到不同邻居规模的影响。如在推荐常见中,某些item和很多用户交互,另一些item可能只有很少的用户交互。因此:某些热门节点的embedding可能会被某些弱相关的邻居而损害,而一些冷门节点的embedding可能未能充分学习。无法直接聚合具有不同内容特征的异质邻居。异质邻居的内容可能需要不同的特征变换,从而处理不同的特征类型和特征维度。
针对这些问题并解决问题
C1,我们设计了一种基于重启的随机游走策略(random walk with restart: RWR)来对异质邻居进行采样。RWR包含两个连续的步骤:step1:基于RWR采样固定数量的邻居。我们从节点我们始终执行
RWR直到收集到固定数量的节点,收集到的节点集合记作注意:
step2:对采样的邻居节点集合根据节点类型进行分组。对于节点类型top
由于下列原因,
RWR策略能够避免上述问题:RWR能够为每个节点收集到所有类型的邻居。每个节点采样的邻居规模是固定的,并且访问最频繁的邻居节点(即最相关的)被挑选出来。
根据节点类型对邻居进行分组(每个分组具有相同的内容格式),以便可以设计基于类型的聚合。
1.1.2 异质内容编码
我们设计了一个具有两个模块的异质图神经网络体系结构,从而聚合每个节点的采样后异质邻居的特征信息。
为解决问题
C2,我们设计了一个模块,从节点embedding。具体而言,我们将
Par2Vec来预训练文本内容,可以利用CNN来预训练图像内容。之前的一些方法直接拼接不同的内容特征,或者将不同的内容特征经过线性映射到相同的特征空间。和这些方法不同,我们基于
Bi-LSTM设计了一种新的架构来捕获deep feature interaction,并获得更强的表达能力。因此,节点
embedding为:其中:
embedding,embedding维度。feature transformer),它可以是恒等映射(没有任何变换)、也可以是一个全连接神经网络(参数为LSTM之前,首先进行特征变换。
具体而言,上述架构首先使用不同的
FC层来转换不同的内容特征,然后使用Bi-LSTM来捕获deep feature interaction,并聚合所有内容特征的表达能力。最后取所有隐状态的均值来获得节点embedding。通过内容拼接然后馈入全连接层也可以捕获
deep feature interaction。这里用Bi-LSTM个人觉得不太合理,因为Bi-LSTM强调有序的输入,而这里的输入是无序的。虽然通过随机排列内容集合Bi-LSTM中,但是这仅仅是一种变通方案,而没有很好地捕获到内容信息之间的关联(如互补关系、overlap关系)。注意:
Bi-LSTM应用在无序的内容集合GraphSAGE在聚合无序邻居的启发。我们使用不同的
Bi-LSTM来聚合不同类型节点的内容特征,因为它们的内容类型互不相同。
上述内容
embedding体系结构有三个主要优点:具有较低复杂度的间接架构(参数较少),使得模型的实现和调整都相对容易。
能够融合异质内容信息,具有很强的表达能力。
增加额外的特征很灵活,使得模型扩展很方便。
1.1.3 异质邻居聚合
为聚合每个节点的异质邻居的内容
embedding(问题C3),我们设计了另一个type-based神经网络模块,它包含两个步骤:同一类型的邻居聚合、类型组合。同一类型的邻居聚合:我们使用基于
RWR的策略为每个节点采样固定数量的、包含不同类型的邻居集合,并针对类型topembedding:其中:
embedding向量,embedding维度。CNN网络、或者是RNN网络。这里我们选中
Bi-LSTM,因为实践中它的效果最好。因此:我们使用
Bi-LSTM聚合所有类型为embedding。注意:
我们使用
Bi-LSTM来区分不同节点类型的邻域聚合。Bi-LSTM应用在无序邻居上,这是受到GraphSAGE在聚合无序邻居的启发。
类型组合(
type combination):前面为每个节点embeddingtype-based邻域聚合embedding以及节点的内容embedding,我们采用了注意力机制。我们认为:不同类型的邻域对final embedding做出的贡献不同。因此,节点embedding为:其中:
final embedding。embedding的重要性。embedding,embedding。
定义节点
embedding集合为其中:
LeakyReLU。embedding向量。attention vector),是待学习的参数。
在整个框架中,为了使得
embedding维度一致并且模型易于调整,我们使用相同的维度embedding、节点邻域聚合embedding、节点final embedding。
1.1.4 模型训练
为学习异质图的
node embedding,我们定义目标函数为:其中:
条件概率
softmax函数:final embedding。
我们利用负采样技术来调整目标函数,此时
其中:
noise distributioin。即:对于节点
最终我们的损失函数为:
其中
注意,
类似于
DeepWalk,我们设计了一个随机游走过程来生成首先,我们在异质图中统一生成一组随机游走序列的集合
然后,对于随机游走序列集合
最后,对于每个上下文节点
degree,也等于它在
在训练的每轮迭代中,我们对
mini-batch的三元组,然后通过Adam优化器来更新模型参数。我们反复迭代直到模型收敛为止。
1.2 实验
这里我们进行广泛的实验:
HetGNN在各种图挖掘任务中和SOTA baseline方法的比较,如链接预测、个性化推荐、节点分类&聚类任务。HetGNN在inductive learning任务中和SOTA baseline方法的比较,如inductive节点分类&聚类任务。HetGNN中不同组件(如异质节点内容编码器,异质邻域聚合器)对模型性能的影响。HetGNN中各种超参数(如embedding维度、异质邻居采样大小)对模型性能的影响。
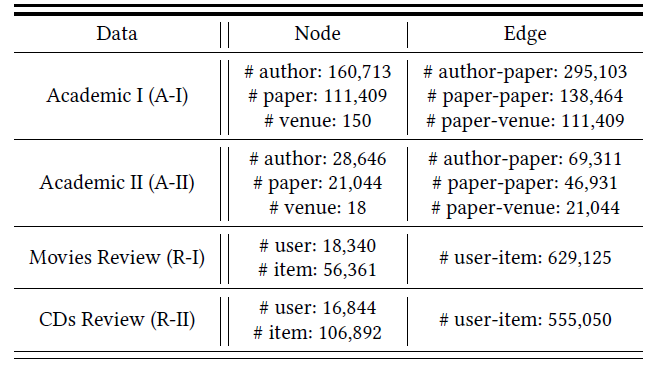
数据集:我们采用两种异质图数据集:学术图(
academic graph)、评论图(review graph)。学术图:我们从
AMiner数据集中抽取两个数据集:A-I包含1996 ~ 2005年之间计算机科学会议的论文。A-II包含2006 ~ 2015年之间若干个人工智能和数据科学相关的顶会的论文,因为考虑到大多数研究人员关注于顶会的论文。
每篇论文都有各种内容信息,包括:标题、摘要、作者、参考文献、年份、所属会议。
评论图:我们从公开的
Amazon数据集抽取了两个数据集,即R-I(电影类别的评论)、R-II(CD类别的评论)。数据集包含1996-05 ~ 2014-07之间用户的评论信息、商品元数据信息。每个商品都有各种内容信息,包括:标题、描述文本、类型、价格、图片。
下表给出了这四个数据集的主要统计信息:
内容特征编码:
在学术网络中,我们使用
ParVec预训练论文的标题和摘要。此外,我们还使用DeepWalk来预训练异质图中所有节点的embedding(将异质图视为同质图来训练)。每个作者节点关联一个预训练的
author embedding(通过DeepWalk得到)、作者的所有论文(经过采样之后)的论文摘要embedding均值(通过ParVec得到)、作者的所有论文(经过采样之后)的论文标题embedding均值。因此,作者的内容编码器的Bi-LSTM的长度为3。每篇论文关联一个预训练的
paper embedding(通过DeepWalk得到)、论文的摘要embedding(通过ParVec得到)、论文的标题embedding(通过ParVec得到)、论文作者预训练embedding的均值(通过DeepWalk得到,一篇论文可能有多个作者)、论文会议的预训练embedding(通过DeepWalk得到)。因此,论文的内容编码器的Bi-LSTM的长度为5。每个会议节点关联一个预训练的会议
embedding(通过DeepWalk得到)、会议中随机抽取的论文的摘要的平均embedding(通过ParVec得到)、会议中随机抽取的论文的标题的平均embedding(通过ParVec得到)。因此,会议的内容编码器的Bi-LSTM的长度为3。
在评论网络中,我们使用
ParVec预训练商品标题和描述内容,用CNN预训练商品图片。此外,我们还使用DeepWalk来预训练异质图中所有节点的embedding(将异质图视为同质图来训练)。每个用户关联一个预训练的用户
embedding(通过DeepWalk得到)、所有用户评论过的(经过采样之后)商品的描述文本embedding均值(通过ParVec得到)、所有用户评论过的(经过采样之后)商品的图片embedding均值(通过CNN得到)。因此,用户的内容编码器的Bi-LSTM长度为3。每个商品关联一个预训练的
item embedding(通过DeepWalk得到)、商品描述文本的embedding(通过ParVec得到)、商品图片的embedding(通过CNN得到)。因此,商品的内容编码器的Bi-LSTM长度为3。
baseline方法:我们使用5个baseline,包括异质图embedding模型、属性网络模型、图神经网络模型。metapath2vec: MP2V:一个异质图embedding模型,它基于metapath指导的随机游走来生成随机游走序列,并通过SkipGram模型来学习node embedding。ASNE:一种属性网络embedding方法,它使用节点的潜在特征和属性来学习node embedding。SHNE:一种属性网络embedding方法,它通过联合优化图结构邻近性和文本语义相似性,从而学习文本相关的异质图的node embedding。GraphSAGE:一个图神经网络模型,它聚合了邻居的特征信息。GAT:一个图注意力网络模型,它通过self-attention机制来聚合邻居的特征信息。
HetGNN的参数配置:embedding维度为128。邻域采样规模:
对于学术网络,邻域采样大小为
23,其中作者节点选择top-10、论文节点选择top-10、会议节点选择top-3。对于评论网络,邻域采样大小为
20,其中用户节点选择top-10、商品节点选择top-10。
对于
RWR,我们选择返回概率RWR序列长度为100(即在获取三元组集合
10,每条随机游走序列长度为30,上下文窗口大小为5。我们使用
Pytorch来实现HetGNN,并在GPU上进行实验。
baseline参数配置:为公平起见,所有
baseline的维度设为128。对于
metapath2vec,对于学术网络我们使用三个metapath:APA(author-paper-author)、APVPA(author-paper-venue-paper-author)、APPA(author-paper-paper-author);对于评论网络我们使用一个metapath:UIU(user-item-user)。每个节点开始的随机游走序列数量为
10,每条随机游走序列的长度为30,这和HetGNN保持一致。对于
ASNE,除了latent特征之外,我们使用HetGNN相同的内容特征,然后将它们拼接为一个通用的属性特征。对于
SHNE,对于两个数据集我们分别利用论文摘要和商品描述(文本序列= 100)作为deep semantic编码器(如LSTM)的输入。此外,随机游走序列的配置和metapath2vec相同。对于
GraphSAGE和GAT,我们使用HetGNN相同的内容特征作为输入特征(拼接为一个通用的属性特征),并将每个节点的采样邻居数量设为和HetGNN相同。
1.2.1 链接预测
之前的做法是:随机采样一部分链接进行训练,然后使用剩余链接用于预测。我们认为应该根据时间顺序来拆分训练集和测试集,而不是随机拆分。
对于学术图,我们令
对于
A-I数据集,我们考虑两种拆分情况:A-II数据集,我们也考虑两种拆分情况:另外,对于学术图我们仅考虑两种类型的边:作者之间的共同撰写关系(
type-1)、作者和论文之间的引用关系(type-2)。对于评论图,我们按顺序拆分。对于
R-I数据集,根据边的数量拆分比例为7:3,对于R-II数据集,根据边的数量拆分比例为5:5。
对于测试集:
删除测试集中重复的边。
随机采样相等数量的“负边”(即不存在的噪音边)加入测试集。
我们使用所有节点 + 训练集的边来学习
node embedding,然后使用训练集的链接来训练逻辑回归分类器。逻辑回归分类器的输入为边的embedding,每条边的embedding是两端node embedding的逐元素乘积。最后,我们使用训练好的分类器来评估测试集,评估指标为
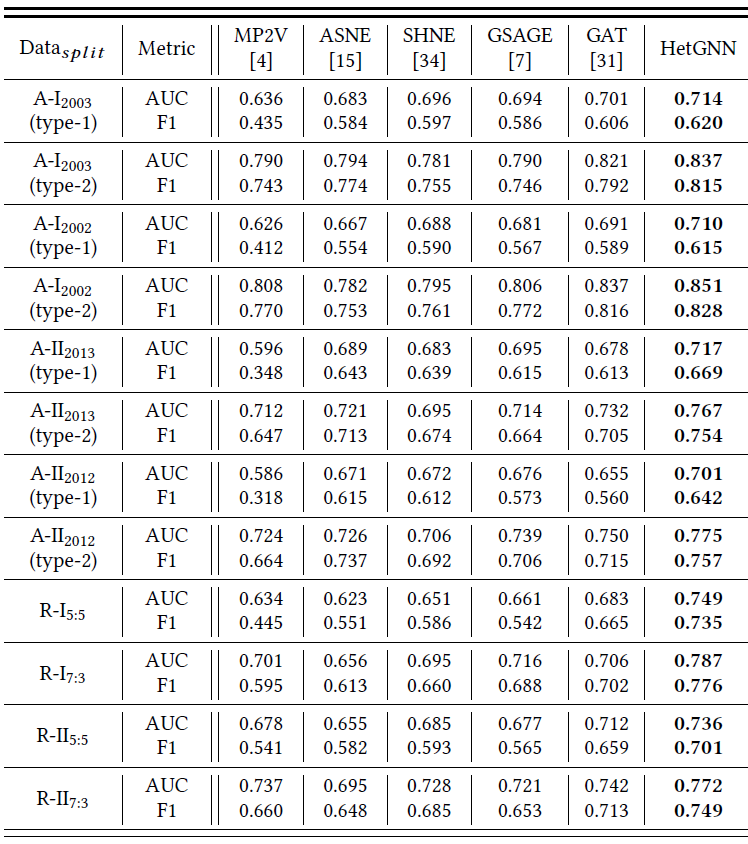
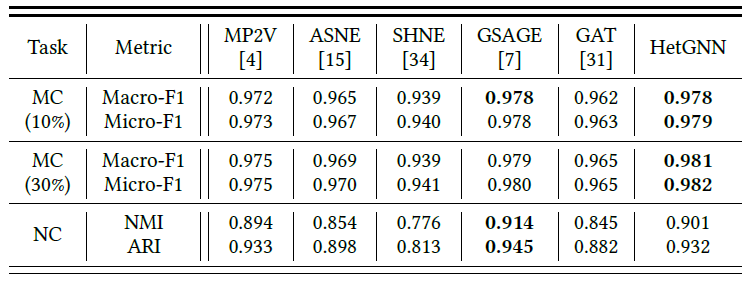
AUC和F1-Score。链接预测结果见下表所示,其中最佳结果以粗体突出显示。
结论:
大多数情况下,最好的
baseline是属性图embedding方法或图神经网络方法,这表明融合节点属性或使用深度神经网络能产生更好的node embedding,从而有利于链接预测。在所有情况下,尤其是评论图中,
HetGNN均优于所有baseline方法。这证明了HetGNN是有效的,它产生了针对链接预测任务更有效的node embedding。
1.2.2 个性化推荐
我们在学术图中评估顶会推荐 (
author-venue链接) 的表现。具体而言,训练数据用于学习node embedding。推荐的ground-truth为:给定测试集中的顶会,作者在测试数据集中出现(发表过论文)。和链接预测任务相同,对于
A-I数据集,我们考虑两种拆分情况:A-II数据集,我们也考虑两种拆分情况:我们采用两个节点的
embedding内积作为推荐分,并挑选top-k推荐分的作者作为推荐列表。对于A-I数据集,k=5;对于A-II数据集,k=3。推荐的评估指标为
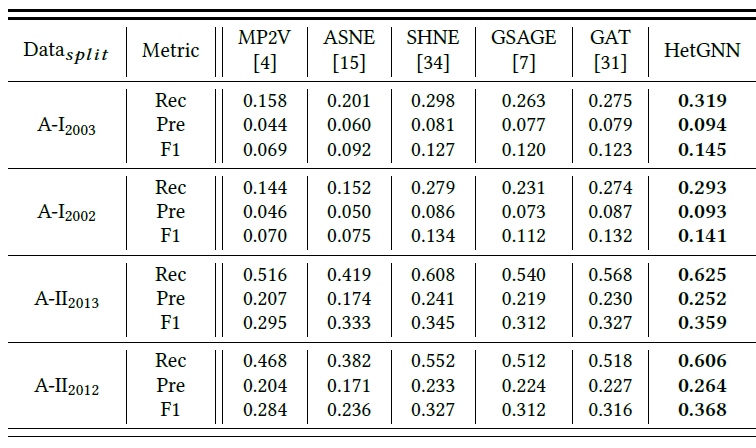
top-k推荐列表的Recall(Rec), Precision(Pre), F1-Score,最终我们给出所有作者的均值作为报告得分。此外,重复的author-venue pair将从评估中删除。个性化推荐结果见下表所示,其中最佳结果以粗体突出显示。
结论:
大多数情况下,最好的
baseline是属性图embedding方法或图神经网络方法,这表明融合节点属性或使用深度神经网络能产生更好的node embedding,从而有利于个性化推荐。在所有情况下,尤其是评论图中,
HetGNN均优于所有baseline方法。这证明了HetGNN是有效的,它产生了针对个性化推荐任务更有效的node embedding。
1.2.3 节点分类&聚类
类似
metapath2vec,我们将A-II数据集中的作者分类到四个选定的研究领域:数据挖掘(data mining:DM)、计算机视觉(computer vision:CV)、自然语言处理(natural language processing:NLP)、数据库(databse:DB)。具体而言,我们为每个领域选择三个热门会议,每个作者标记为他/她大部分论文所属的领域。如果在这些会议中未发表论文的作者将被剔除评估。如果作者在这些会议的多个领域发表过论文,则作者为多个标签。因此这是一个多标签节点分类问题。
我们从完整数据集中学习
node embedding,然后将学到的node embedding来作为逻辑回归分类器的输入。我们将带标记的节点随机拆分,训练集的大小从10%~30%,剩余节点作为测试集。评估指标为测试集的Micro-F1和Macro-F1。对于节点聚类任务,我们将学到的
node embedding作为聚类模型的输入。这里我们采用Kmeans算法作为聚类算法,然后采用NMI和ARI作为评估指标。下表给出了所有方法的评估结果,最佳结果以粗体突出显示。
结论:
大多数模型在多标签分类任务中表现良好,并得到较高的
Macro-F1和Micro-F1指标。这是因为这四个选定领域的作者彼此完全不同,分类相对容易。尽管如此,
HetGNN在多标签分类和节点聚类方面仍然达到了最佳性能或者可比的性能。这证明了HetGNN是有效的,它产生了针对节点分类和聚类任务更有效的node embedding。
此外,我们还通过
tensorflow embedding projector来可视化四个领域作者的embedding。我们随机采样了100位作者,如下图所示分别位2D可视化和3D可视化。可以看到:同类别作者的
embedding紧密地聚集在一起,从而证明了学到的node embedding的有效性。
1.2.4 inductive 节点分类&聚类
该任务的配置和之前的节点分类&聚类任务类似,不同之处在于:我们对
A-II数据集进行按年份拆分,拆分年份为2013,然后将2013年以及之前的数据作为训练集、之后的数据作为测试集。我们用训练集中的数据来训练模型并得到训练集中节点的
embedding,然后用训练好的模型来推断测试集中新节点的embedding。最后我们使用推断的新node embedding来作为分类和聚类模型的输入。注:逻辑回归分类器使用训练集中的节点来训练。
下表给出了
inductive节点分类和聚类任务的结果,其中最佳结果以粗体显示。结论:
大多数模型在
inductive多标签分类任务中表现良好,并得到较高的Macro-F1和Micro-F1指标。这是因为这四个选定领域的作者彼此完全不同,分类相对容易。尽管如此,
HetGNN在inductive多标签分类任务中仍然达到了最佳性能或者可比的性能HetGNN在inductive节点聚类任务中优于所有其它方法。
结果表明
HetGNN模型可以有效地推断新节点的embedding。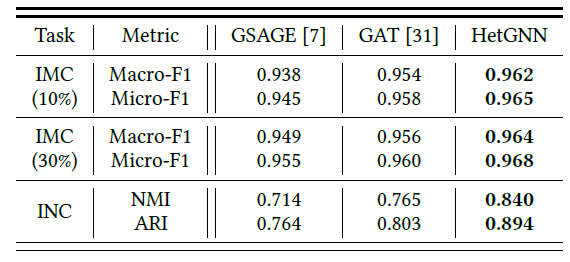
1.2.5 消融研究
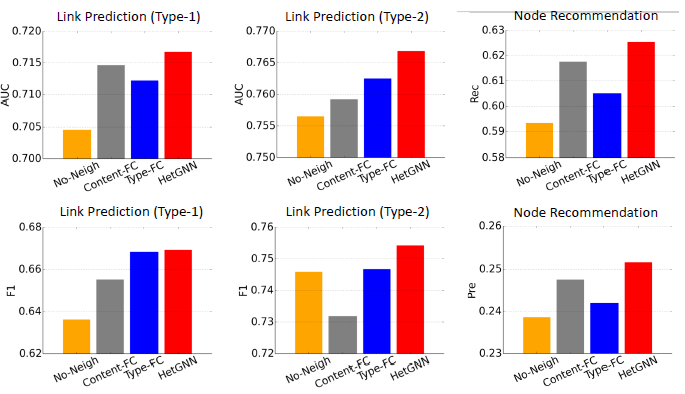
我们考察了
HetGNN模型的几种变体:No-Neigh:直接使用异质内容编码来表示每个节点的embedding,不考虑邻居信息。即:Content-FC:使用全连接层来作为异质内容编码器,从而代替Bi-LSTM。Type-FC:使用全连接层来融合不同邻居类型的embedding,而不是BiLSTM + attention。
下图报告了
A-II数据集(训练集--测试集拆分年份2013)上链接预测和节点推荐的结果。结论:
大多数情况下,
HetGNN性能优于No-Neigh,这表明聚合邻域信息对于生成更好的node embedding是有效的。HetGNN优于Content-FC,这表明基于Bi-LSTM的内容编码要比浅层编码器(如全连接层)要更好,Bi-LSTM可以捕获深度的内容特征交互。HetGNN优于Type-FC,这表明在捕获节点类型的影响方面,基于attention机制要优于全连接层。
1.2.6 参数敏感性
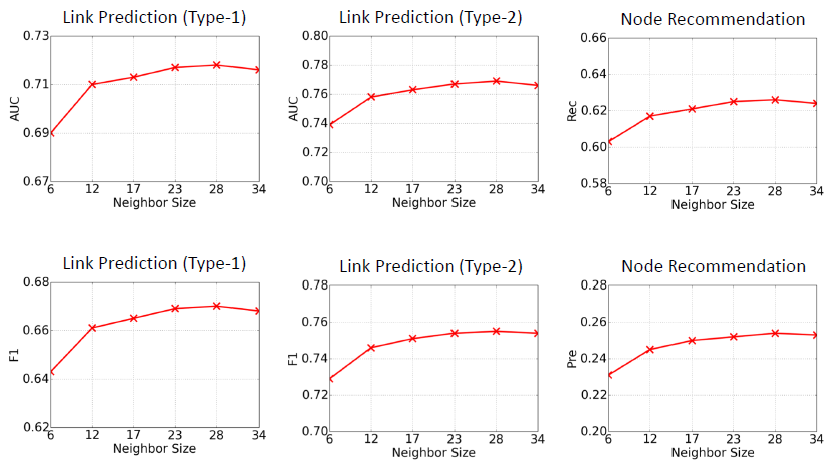
我们考察
HetGNN链接预测和推荐的性能随embedding维度A-II训练集上评估,训练集--测试集拆分年份位2013。当固定采样邻居规模(设为23),我们选择不同的结论:当
8增加到256时,所有指标都会增加,因为学到了更好的embedding。但是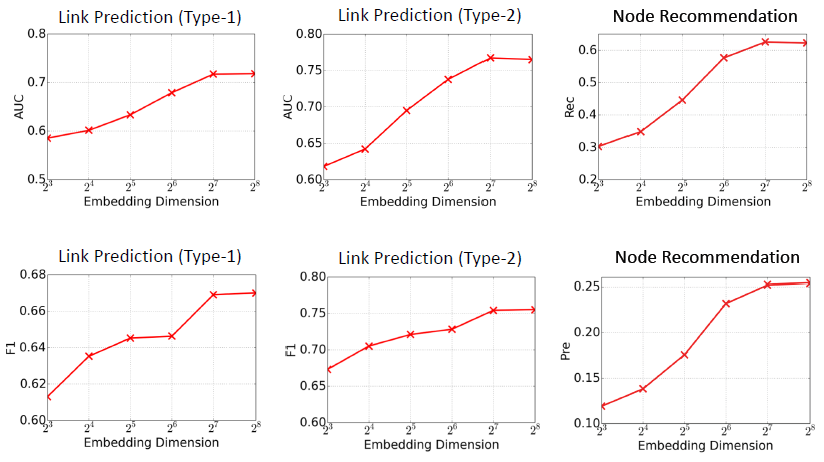
我们考察
HetGNN链接预测和推荐的性能随样本邻域大小的影响。我们在A-II训练集上评估,训练集--测试集拆分年份为2013。当固定embedding维度top6 = 2 (author) + 2 (paper) + 2 (venue)12= 5 (author) + 5 (paper) + 2 (venue)17 = 7 (author) + 7 (paper) + 3(venue)23 = 10 (author) + 10 (paper) + 3 (venue)28 = 12 (author) + 12 (paper) + 4 (venue)34 = 15 (author) + 15 (paper) + 4 (venue)结论:当邻域大小从
6增加到34时,所有指标都会增加,这是因为考虑了更多的邻域信息。但是当邻域规模超过某个值时,性能可能会缓缓降低,这可能是因为涉及到不相关的(噪音)邻居导致。最佳邻域大小为20 ~ 30。